
Images, metadata, orphans and copyright
Originally posted as a CREATe blog. CREATe is the RCUK funded Centre for Copyright and New Business Models in the Creative Economy.
Coincidentally, five days after the publication of the Copyright Licensing Steering Group's report on the last 12 months of work on streamlining copyright, I was due to give a talk at a joint event of CREATe and the EPSRC funded Network of Excellence in Identity. The event "Identity Lost – electronic identity, digital orphan works and copyright law reform", the talk "Digital tool chains; get your act together" - what joy to find the CLSG report, which lays down 10 key principles, formed the perfect frame to what I had planned to talk about! What should we do to avoid the on going creation of digital works that are orphans at birth?
Herewith the blogged version of the talk...
Metadata matters: encourage its use and preservation
I. By default create and preserve metadata
What is metadata in a digital image? Simply data attached to the digital image written by the camera when the image is created or afterwards as the image is processed by various tools. Nearly all cameras (including smartphones) capture information about the "camera" - lens, aperture, timing, resolution etc. - and the when and (especially with smartphones) the where. (More here.)
Professionals are well served when it comes to information concerning copyright and licensing; high end cameras from the likes of Nikon and Canon have for years had the facility to add this metadata. However, the vast majority of images created by digital cameras today are created without any ownership information; so a first step would be to fix that in all consumer and pro-am cameras; it is especially galling that with all the personal information held about me in my smartphone the software doesn't get around to adding any useful identifying metadata to the images it creates.
Attach correct and meaningful metadata to your work so that others can find you or your agent
II. If you wish to claim credit you need to be contactable
Licensing metadata needs to include the means to make contact with the creator or their agent. The latter an important point for a creator seeking some degree of anonymity or separation of identities, yet maintaining control of their work - a recent high profile example being that of J. K. Rowling and her alter ego Robert Galbraith.
 In this day and age - a unique URI per creator identity seems like a good idea - a raft of these already exist, for example OpenID. It's not clear to me that anything specific is required other than
In this day and age - a unique URI per creator identity seems like a good idea - a raft of these already exist, for example OpenID. It's not clear to me that anything specific is required other than
exist the service to enable contact to be made to the owner of an OpenID, and with certain providers it's no more than a blogpost. In future the appropriate URI might be as link to content licensable on a digital copyright exchange (DCX) such as proposed by the Copyright Hub.
Actually, besides who, it might be really useful to include possible default licenses, especially if it something well understood like a Creative Commons license. It does raise the interesting question that if you assign CC0 (no rights reserved) license can you forgo the need for identification...
Support technology that makes it easy for you to include metadata
III. Use tools that by default maintain metadata
Jolly good idea. Name and shame those that do not.
IV. Embed a unique identifier in the metadata
As with the copyright identifier, URIs could stand us in good stead, e.g. http://ddmoid.files.wordpress.com/2013/11/img_9938.jpg
Check before use: always look for metadata
V. Take reasonable steps to find metadata
At one level if we have created metdata, used tools to maintain it, or at least have a unique identifier such as a URI embedded, finding the metadata in the digital age should be easy and operate instantaneously.
However, what constitutes reasonable steps if the metadata is not attached to the image - a talk at the same workshop by the Scottish National Library put a "due diligence" search at 4 hours per image and often came back with nothing. Some technology might help - PicScout provides a browser plug-in that identifies registered images in webpages, but is not fool proof. The image on the right was tagged by PicScout as "rights managed" because 1000s of tourists (myself included) and at least one photographer using Getty Images have photographed the same temple in Egypt from about the same spot, and it's usually sunny and a blue sky. It does mean it's probably not that valuable an image...
Do not ignore licensing metadata included with an image
VI. If it is there use it!
Work within the law
VII. Obtain a license.
For some images, the metadata might include a quite permissive license (e.g. Creative Commons), for others you may need to contact the owner by following the URI trail, but the hope is that in future you find yourself at a DCX where a simple online transaction obtains you a license. One major challenge to automating this process is the degree to which many works are licensed for use in a specific context - for example an image for use in a company report would not cost the same as one used for the front cover of OK magazine...
If in doubt do not use
VIII. Absence of metadata is not a right to use.
There is a major implication in this for all those photo-sharing sites - if there is no licensing metadata should they permit images to be uploaded? At one level this seems extreme, but if in the future all cameras generated this metadata, most legitimate photo-sharing users would not even know the difference.
Do not break the chain: maintain the connection to the rights holder
IX. Don’t remove metadata
Indeed if you find damaged metadata, you might want to fix it...
If you must remove metadata from the original file, store it elsewhere
X. Maintain metadata associated with image somewhere
The final point her feels to me like it should be transitionary guidance; I'm wracking my brains to figure out a technical reason this would be necessary and drawing a blank - yes many pieces of software that do this by default need fixing, but why not give the industry, say 3 years, to get their collective acts together and get back to the naming and shaming game.
There is one final evilness in the big scheme of creating new pictures - what I have done on the right here - the screen capture. This means of digital copying currently does not preserve metadata, as most windowing systems deal in pixels, not having a concept that a particular arrangement of pixels may have a license associated with them. Hmm, no reason it couldn't - there's a paper in that...
In conclusion, there do seem to be a set of quite simple technical means by which we could bring a lot more tidiness to the management of digital imagery; perhaps some device, software and service vendors should seek market advantage by being first movers in getting their act together. And there's certainly a fruity one that does all in a vertically integrated offering.
Coincidentally, five days after the publication of the Copyright Licensing Steering Group's report on the last 12 months of work on streamlining copyright, I was due to give a talk at a joint event of CREATe and the EPSRC funded Network of Excellence in Identity. The event "Identity Lost – electronic identity, digital orphan works and copyright law reform", the talk "Digital tool chains; get your act together" - what joy to find the CLSG report, which lays down 10 key principles, formed the perfect frame to what I had planned to talk about! What should we do to avoid the on going creation of digital works that are orphans at birth?
Herewith the blogged version of the talk...
Metadata matters: encourage its use and preservation
I. By default create and preserve metadata
What is metadata in a digital image? Simply data attached to the digital image written by the camera when the image is created or afterwards as the image is processed by various tools. Nearly all cameras (including smartphones) capture information about the "camera" - lens, aperture, timing, resolution etc. - and the when and (especially with smartphones) the where. (More here.)
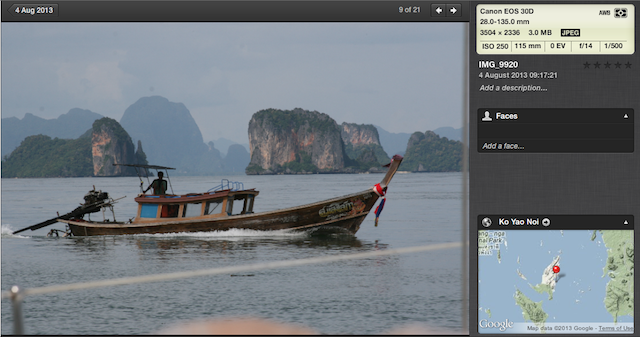 |
| (C) Derek McAuley; not really sufficient... |
Professionals are well served when it comes to information concerning copyright and licensing; high end cameras from the likes of Nikon and Canon have for years had the facility to add this metadata. However, the vast majority of images created by digital cameras today are created without any ownership information; so a first step would be to fix that in all consumer and pro-am cameras; it is especially galling that with all the personal information held about me in my smartphone the software doesn't get around to adding any useful identifying metadata to the images it creates.
Attach correct and meaningful metadata to your work so that others can find you or your agent
II. If you wish to claim credit you need to be contactable
Licensing metadata needs to include the means to make contact with the creator or their agent. The latter an important point for a creator seeking some degree of anonymity or separation of identities, yet maintaining control of their work - a recent high profile example being that of J. K. Rowling and her alter ego Robert Galbraith.
exist the service to enable contact to be made to the owner of an OpenID, and with certain providers it's no more than a blogpost. In future the appropriate URI might be as link to content licensable on a digital copyright exchange (DCX) such as proposed by the Copyright Hub.
Actually, besides who, it might be really useful to include possible default licenses, especially if it something well understood like a Creative Commons license. It does raise the interesting question that if you assign CC0 (no rights reserved) license can you forgo the need for identification...
Support technology that makes it easy for you to include metadata
III. Use tools that by default maintain metadata
Jolly good idea. Name and shame those that do not.
IV. Embed a unique identifier in the metadata
As with the copyright identifier, URIs could stand us in good stead, e.g. http://ddmoid.files.wordpress.com/2013/11/img_9938.jpg
{kind=link}
Check before use: always look for metadata
V. Take reasonable steps to find metadata
At one level if we have created metdata, used tools to maintain it, or at least have a unique identifier such as a URI embedded, finding the metadata in the digital age should be easy and operate instantaneously.
 |
| (C) Derek McAuley - really it is |
Do not ignore licensing metadata included with an image
VI. If it is there use it!
Work within the law
VII. Obtain a license.
For some images, the metadata might include a quite permissive license (e.g. Creative Commons), for others you may need to contact the owner by following the URI trail, but the hope is that in future you find yourself at a DCX where a simple online transaction obtains you a license. One major challenge to automating this process is the degree to which many works are licensed for use in a specific context - for example an image for use in a company report would not cost the same as one used for the front cover of OK magazine...
If in doubt do not use
VIII. Absence of metadata is not a right to use.
There is a major implication in this for all those photo-sharing sites - if there is no licensing metadata should they permit images to be uploaded? At one level this seems extreme, but if in the future all cameras generated this metadata, most legitimate photo-sharing users would not even know the difference.
Do not break the chain: maintain the connection to the rights holder
IX. Don’t remove metadata
Indeed if you find damaged metadata, you might want to fix it...
If you must remove metadata from the original file, store it elsewhere
X. Maintain metadata associated with image somewhere
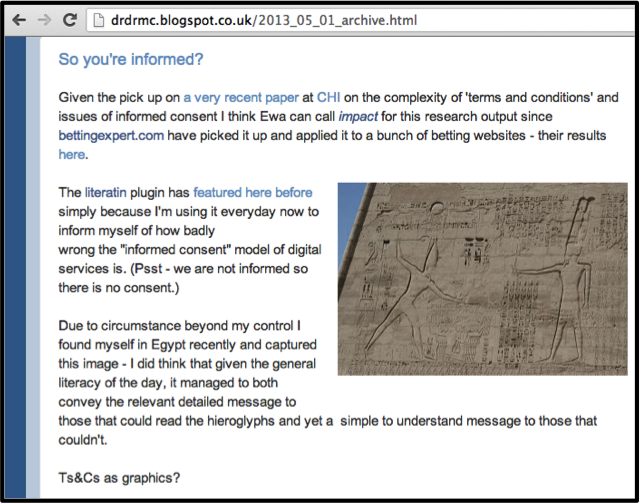 |
| New windowing systems required... |
There is one final evilness in the big scheme of creating new pictures - what I have done on the right here - the screen capture. This means of digital copying currently does not preserve metadata, as most windowing systems deal in pixels, not having a concept that a particular arrangement of pixels may have a license associated with them. Hmm, no reason it couldn't - there's a paper in that...
In conclusion, there do seem to be a set of quite simple technical means by which we could bring a lot more tidiness to the management of digital imagery; perhaps some device, software and service vendors should seek market advantage by being first movers in getting their act together. And there's certainly a fruity one that does all in a vertically integrated offering.
Written on November 15, 2013